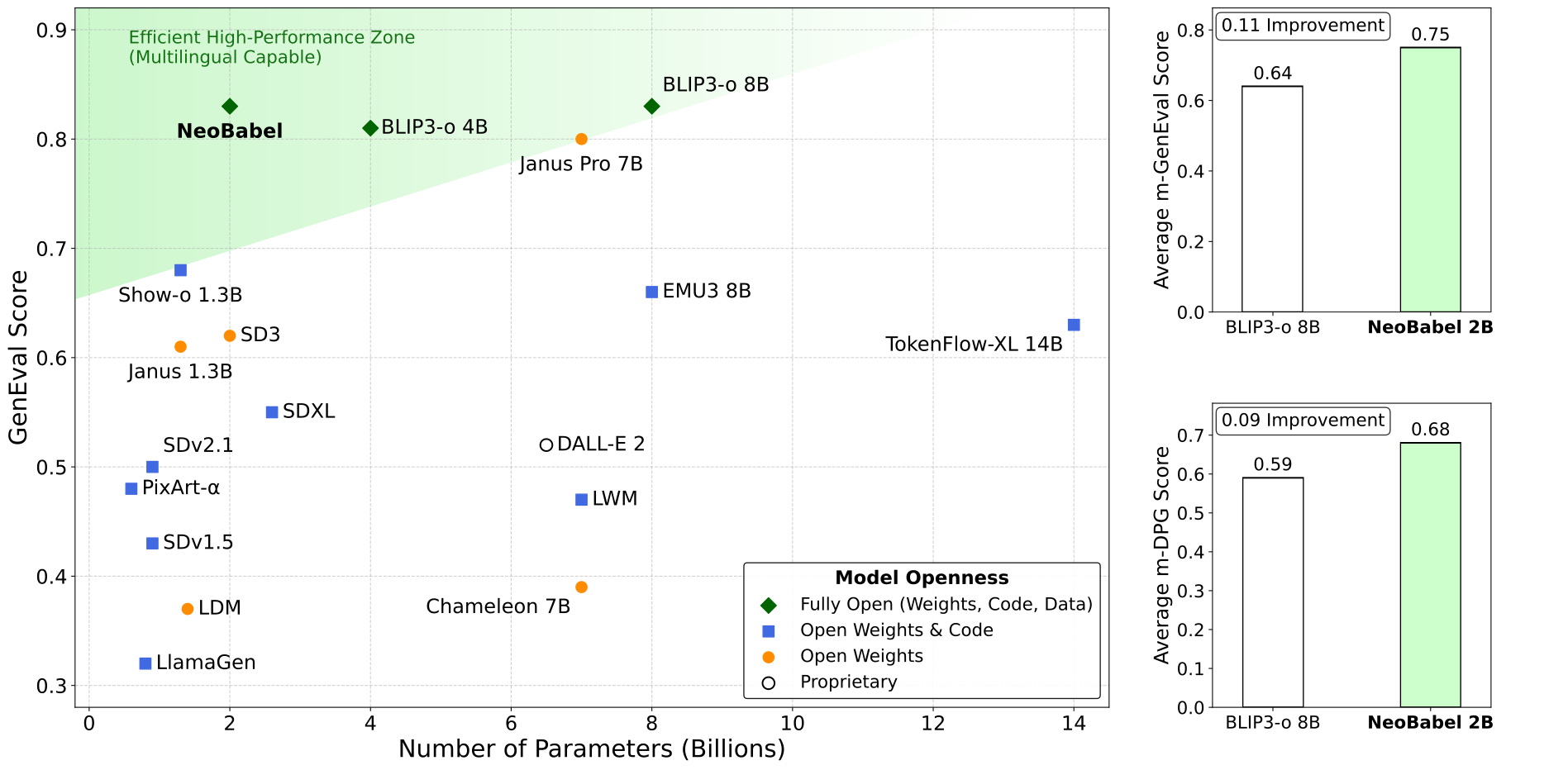
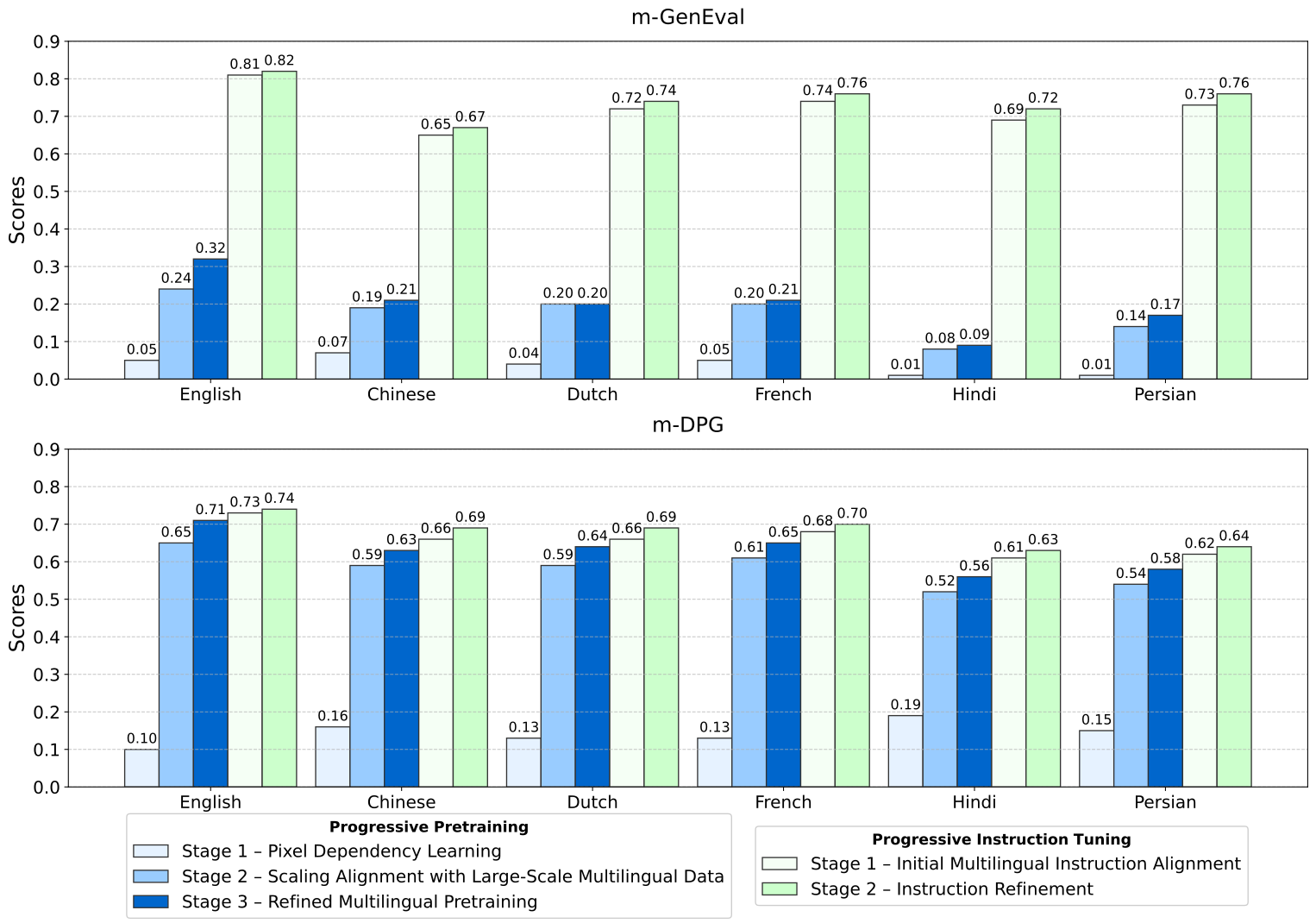
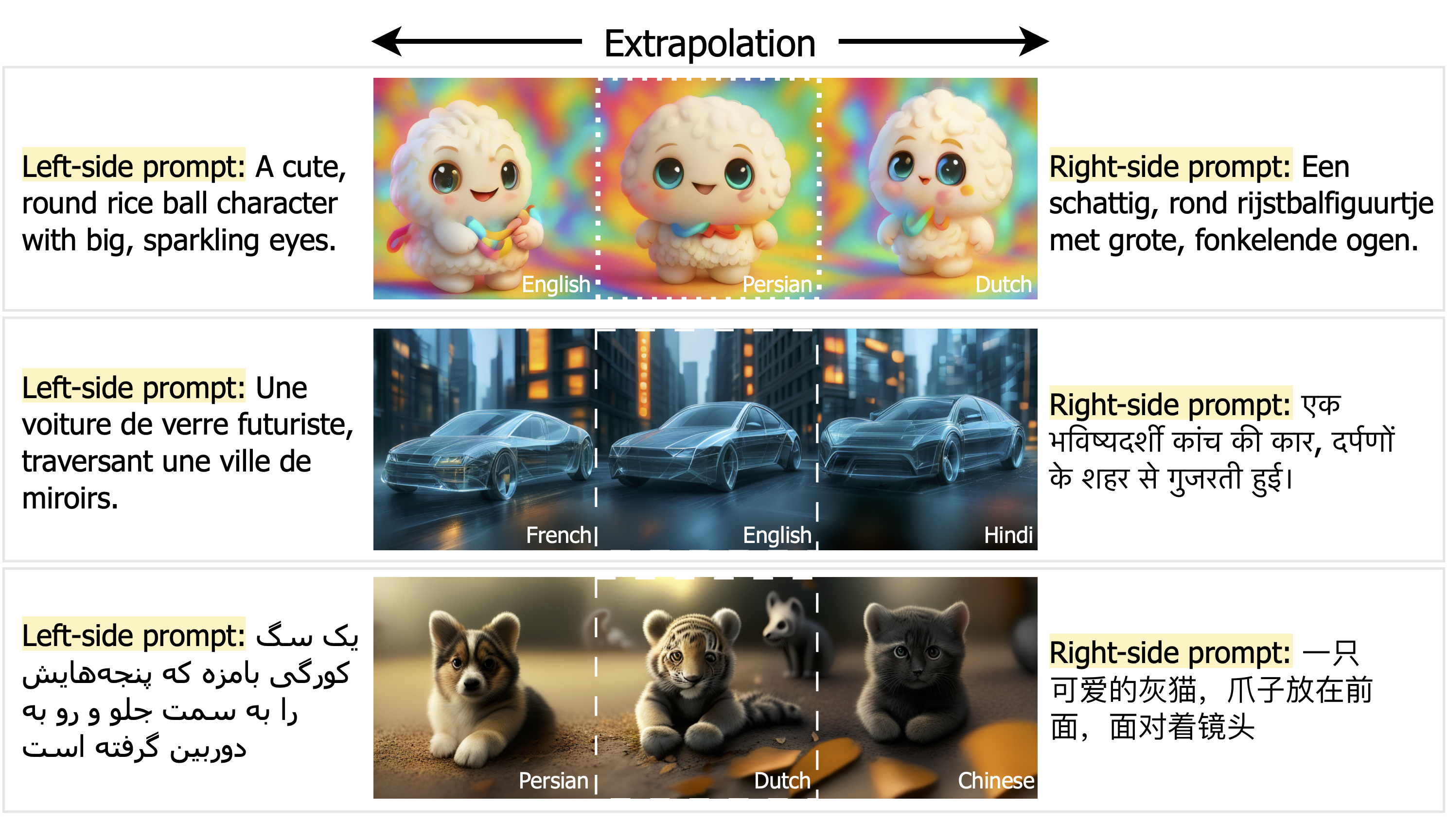
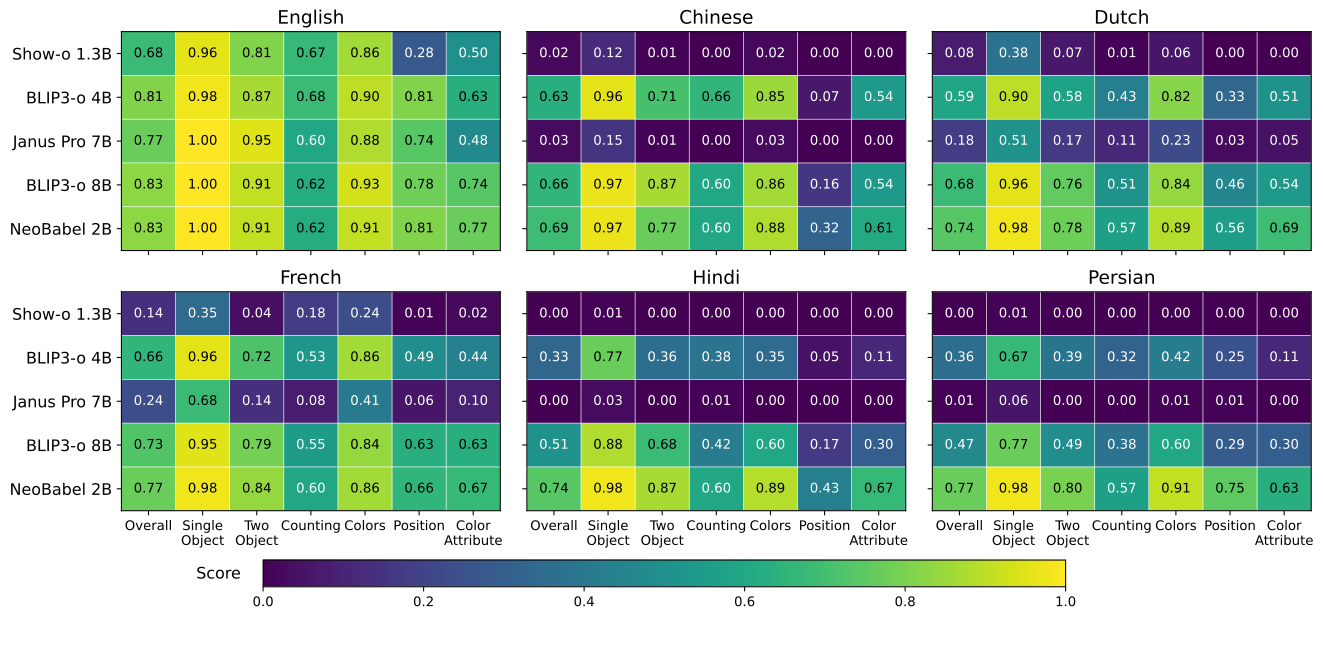
Text-to-image generation advancements have been predominantly English-centric, creating barriers for non-English speakers and perpetuating digital inequities. While existing systems rely on translation pipelines, these introduce semantic drift, computational overhead, and cultural misalignment. We introduce NEOBABEL, a novel multilingual image generation framework that sets a new Pareto frontier in performance, efficiency and inclusivity, supporting six languages: English, Chinese, Dutch, French, Hindi, and Persian. The model is trained using a combination of large-scale multilingual pretraining and high-resolution instruction tuning. To evaluate its capabilities, we expand two English-only benchmarks to multilingual equivalents: m-GenEval and m-DPG. NEOBABEL achieves state-of-the-art multilingual performance while retaining strong English capability. Notably, it performs on par with leading models on English tasks while outperforming them by +0.11 and +0.09 on multilingual benchmarks. We release an open toolkit, including all code, model checkpoints, a curated dataset of 124M multilingual text-image pairs, and standardized multilingual evaluation protocols, to advance inclusive AI research.
 NeoBabel: A Multilingual Open Tower for Visual Generation
NeoBabel: A Multilingual Open Tower for Visual Generation